如何0到1构建一个前端错误上报系统
发布时间: 2025-05-17
前言
最近几年我会在需求不多的时候,做一些基础建设,比如远程调试平台、通用存储服务、错误上报这些,这次我想先聊个简单的东西,也算是讲述一下我从0到1构建一个 前端错误上报平台的过程,其实在我们公司内部是有一些错误上报、性能收集平台的,但是因为一些原因都不是很活跃了,加上有些“重”,或者有些使用上的bug,于是 也就想亲自上阵手搓一个出来,在我们这边几乎每天都会发版,但是由于是内部系统,所以经常会发布了之后产生一些运行时错误,要在使用的过程中不经意的会被发现,而不能及时的发现。 我的初衷有两点,第一个点就是能够及时的发现错误,并且能够推动程序员去修复这些错误。有的错误它不是很紧急,或者说是可以忽略的,程序员就很容易产生不想要去管的想法。 事实上,这些错误对于系统来说的话,是有安全隐患的,如果说累积的足够多的时候,就可能产生一些影响。
基于前面的两个初衷,所以我从去年开始手搓了一个错误上报的系统。
架构
这套系统的设计架构上是分为SDK、服务端、数据库以及一个查看错误数据、处理错误数据的后台,他们的关系是这样的,来一个简易的系统关系图帮助大家理解一下:
┌───────────────┐ ┌───────────────┐
│ 用户浏览器 │ │ 程序员 │
└───────┬───────┘ └───────┬───────┘
│ │
│ ▼
│ ┌───────────────┐
│ │ 后台系统 │
│ └───────┬───────┘
▼ │
┌───────────────┐ ┌──────▼────────┐
│ SDK │◄──────────────►│ 服务端 │◄────────────►┌───────────────┐
└───────────────┘ └───────┬───────┘ │ 数据库 │
│ └───────┬───────┘
└──────────────────────────────┘它的整体工作流程是:
- 用户访问我们的业务系统,业务系统中加载错误采集、上报sdk
- 用户发生运行时错误后上报给服务端
- 服务端清洗数据、落库
- 服务端主动推送错误告警给到程序员/程序员也可以主动通过后台系统观测错误数据、处理错误
sdk的设计
Sdk是错误上报的重点部分,它是用户浏览器和程序员之间的桥梁,如果说SDK的设计不够稳定,不够轻量化,那么对业务的系统的影响可能就会比较明显, 比如说不够轻量化,会导致业务系统的加载速度产生影响,如果说不够稳定,还可能出现错误的时候,反而影响业务系统的使用。因此, SDK的设计首要目标是:
- 轻量化,尽量做到小巧,不光是逻辑尽量少,还要逻辑尽量简单
- 稳定性,做足容错处理
sdk安装方式
SDK的安装方式,通常我们可以选择两种安装方式
- 开发依赖包发布到npm
- 直接打包umd单文件发布cdn
我先说一下,最终我选择的是 umd单文件格式 ,直接挂到cdn,然后我来说说我为什么要选择单文件,而不是npm包安装。
| 方式 | npm包 | umd单文件 |
|---|---|---|
| 业务系统首次接入 | npm i | script标签加载 |
| 更新方式 | 修改代码->构建->发布到npm->业务系统更新依赖->业务系统发布 | 修改代码->构建->发布到cdn |
| 版本管理 | 严格(SemVer) | 手动维护 |
我简单的罗列这几点,主要的原因是我们的系统相对来说控制权都在我们自己的团队手上,只是业务系统数量比较多,如果采用npm包安装,每次更新对大量的业务系统更新来说 是比较痛苦的,我更希望的是SDK的修改能 够快速的更新到各个业务系统,而不是用太考虑破坏性的更新影响其他业务系统,首先我们自己会尽力避免兼容性问题,如果确实不能兼容,则会协同业务系统一起改造。
业务系统只需要使用 script 标签加载我们挂到cdn的单文件sdk.js就行了。
sdk的优化
对于一些比较大的依赖包做单独拆分,比如html2canvas包比较大,不构建到sdk中,独立js挂cdn,根据是否需要截图的需要再延迟加载。
plugins: [
...
new CopyWebpackPlugin({
patterns: [
{
from: path.resolve(cwd, './src/client/sdk/capture.js'),
to: path.resolve(cwd, './andebugger/capture.js'),
},
],
}),
// new BundleAnalyzerPlugin()
],这里将截图的代码直接copy到构建目录,后期直接上传到cos去挂cdn:
try {
if (window.html2canvas) {
getImg();
return;
}
// 环境变量读取cdn这个包的地址
loadJs((process.env.HTML2CANVAS_URL), () => {
if (!window.html2canvas) {
res({ img: '', hash: '' });
return;
}
getImg();
});
} catch {
res({ img: '', hash: '' });
}现在出了一个最新的替代者,据说是性能快几十倍的 SnapDom ,但是也有人说实现差不多,反而覆盖场景变少了,但是对于性能有要求的场景可以尝试一下。
上报内容
错误上报的部分的话,我目前是让SDK支持了运行时错误的采集与上报,以及网络请求的错误已上报。因此我们这套错误上报系统对错误的分类就是这两大类。
| 运行时错误 | 网络请求错误 |
|---|---|
| 运行过程中产生的js错误 | 网络请求错误,比如定向采集4xx、5xx的错误 |
通过提取他们的公共特征,我定义了一套错误数据结构:
reqId?: string; // 用于多次提交同一错误数据
errId: string; // 错误id,对错误计算哈希值
sdkInstanceId: string; // sdk的实例Id
type: ErrorType; // 错误类型,运行错误/网络错误
ua: string; // 浏览器ua
uin: string; // 用户标志
page: string; // 发生错误的页面
path?: string; // 发生错误的path,path和页面分离是为了方便对数据做统计、区分
latestReq?: ReqItem[]; // 错误发生时的一部分请求情况
capture?: CaptureItem; // 截图数据
simple: boolean; // 当前上报是否是简洁模式
sdkver?: string; // sdk的版本号
reportEnv?: string; // 上报的环境,比如prod、test、dev这是基础数据,对于运行时错误会有如下数据
msg?: string;// 错误信息
name?: string;// 错误标题
stack?: Stack[];// 错误堆栈
more?: string;// 更多数据,用于有些犹豫浏览器权限导致无法获取到错误信息的,直接把整个错误序列化上报对于网络错误则会有如下数据
url?: string; // 错误url
method?: string; // 请求方式
status?: string; // 请求状态
statusText?: string; // 状态名称
body?: string; // 请求
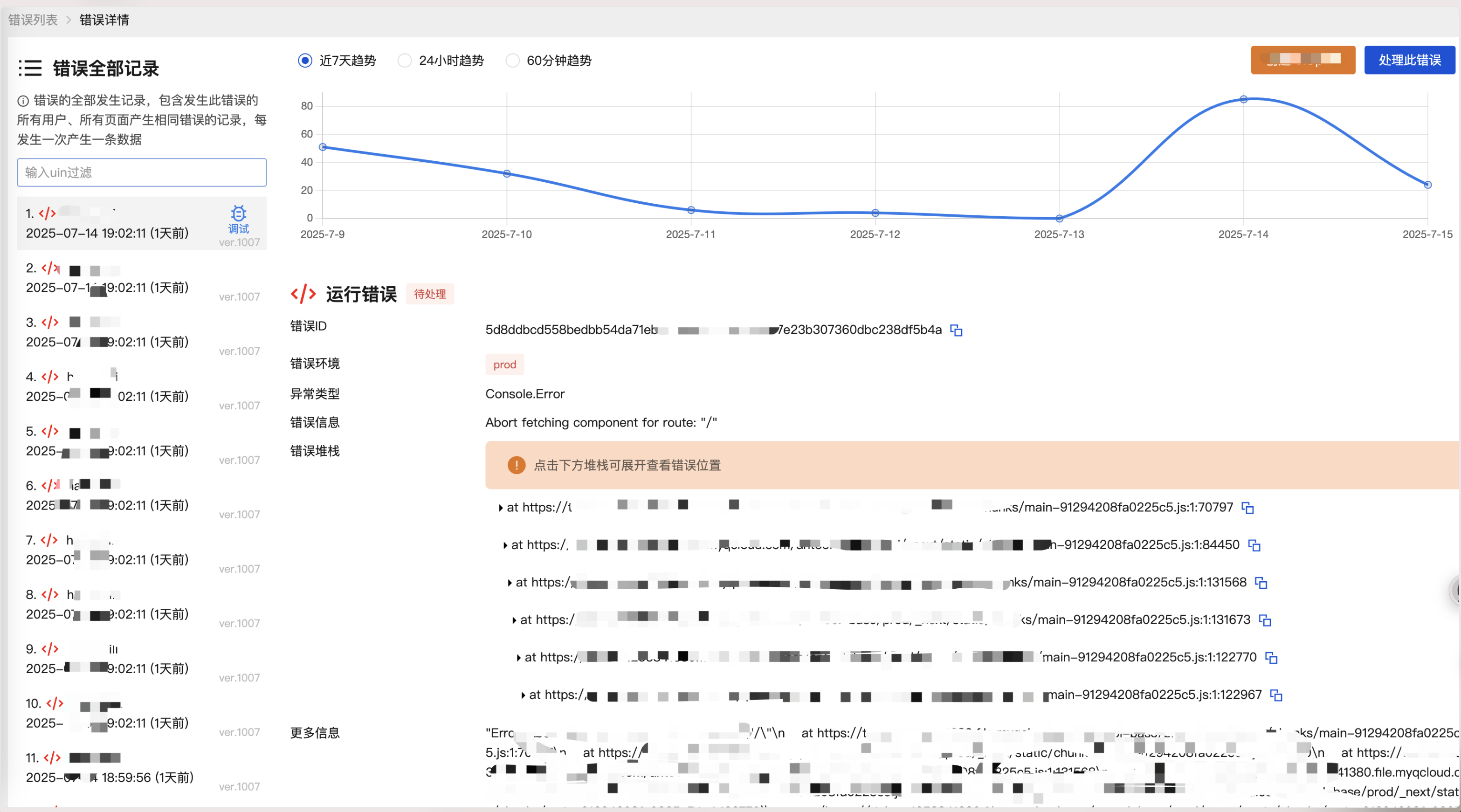
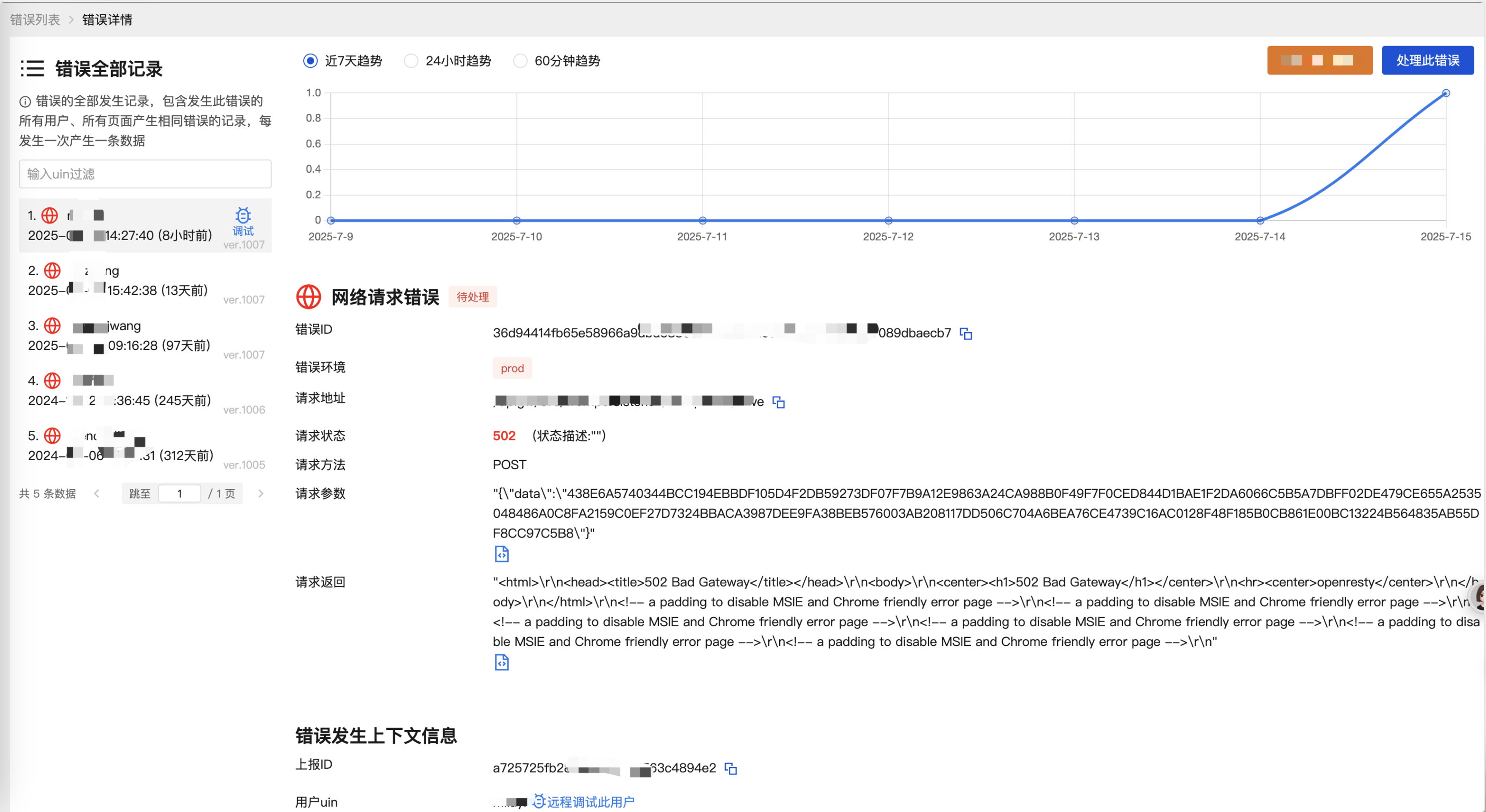
response?:string; // 返回运行错误:

网络错误:
错误采集及策略
运行时采集
运行时采集主要依赖于监听 addEventListener 的 error 事件以及 unhandledrejection 事件,前者主要是监听系统的错误,
后者主要是监听一些没有处理的Promise错误。
核心代码如下
window.addEventListener('error', (e) => {
// console.log(e, 'error错误');
if (e.error || e) {
sendOnInited(exceptionThrown(e.error, e), 1);
} else {
console.error('has no Error Details');
}
}, true);
window.addEventListener('unhandledrejection', (e) => {
// console.log(e, 'promise 错误');
if (e.reason || e) {
if (e && e.reason.request instanceof XMLHttpRequest) {
return;
}
sendOnInited(exceptionThrown(e.reason, e), 1);
} else {
console.error('Unhandled rejection with no reason provided');
}
});
// exceptionThrown 用于分析不同的错误类型,把他们的数据结构抹平
const nativeConsoleFunc = window.console['error'];
window.console['error'] = (...args) => {
nativeConsoleFunc(...args);
const errorDetails = {
msg: (args?.[0]?.message ?? args?.[0]) || '',
name: 'Console.Error',
more: safeStringify((args?.[0]?.stack ?? args?.[0]) || args),
stack: getCallFrames(args?.[0] ?? null),
};
setTimeout(() => {
sendOnInited(errorDetails, 1);
}, 0);
};额外补充一个劫持 console.error 的原因是因为浏览器安全性的问题,有些错误是无法被监听到的,像请求失败、跨域的这些请求是拿不到错误信息的,
比如有些错误详情就是这个:
{
"isTrusted": true
}又或者错误是错误内容就只是一句:
Script error.而劫持 console.error 之后,可以尽量补采到一部分内容的,但是对于推测原因帮助不是特别明显,毕竟为了安全部让js获取错误详细,你肯定是无法突破的。
只是从错误采集系统本着专业的角度来说,应该感知到这些错误的发生。
网络采集
对于网络错误的采集则主要是劫持 fetch 和 XMLHttpRequest 来监视错误,核心逻辑如下:
const originalFetch = window.fetch;
window.fetch = async function (...args) {
...
try {
const response = await originalFetch.apply(this, args);
...
if (!response.ok) {
// todo 上报错误
sendOnInited({
url,
method,
body: safeStringify(body),
status: response?.status || '0',
statusText: safeStringify(response.statusText),
response: subStr(safeStringify(await response.clone().text()), config.REP_SUBSTR_LEN),
}, 2);
}
return response;
} catch (error) {
sendOnInited(exceptionThrown(error?.error ?? error), 1);
throw error;
}
};
const originalOpen = XMLHttpRequest.prototype.open;
const originalSend = XMLHttpRequest.prototype.send;
const originalSetRequestHeader = XMLHttpRequest.prototype.setRequestHeader;
// @ts-ignore
XMLHttpRequest.prototype.open = function (method, url, ...rest) {
...
// @ts-ignore
return originalOpen.apply(this, [method, url, ...rest]);
};
XMLHttpRequest.prototype.setRequestHeader = function(header, value) {
...
return originalSetRequestHeader.apply(this, [header, value]);
};
XMLHttpRequest.prototype.send = function (body) {
...
const onReadyStateChange = () => {
if (this.readyState === 4) {
...
if (this.status < 200 || this.status >= 400) {
sendOnInited({
// @ts-ignore
url: this._url,
// @ts-ignore
method: this._method,
// @ts-ignore
body: safeStringify(this._body),
status: this.status || '0',
statusText: safeStringify(this.statusText),
response: subStr(safeStringify(this.responseText), config.REP_SUBSTR_LEN),
}, 2);
}
}
};
...
};数据体积缩减策略
为了减少上报数据的体积,我对上报数据做了两个大的处理策略,核心思想就是 尽量不上报 、 压缩报文。
尽量不上报
对于尽量不上报这件事情来说的话,我的做法是给错误计算一个哈希值,然后在本地做缓存,通过hash计算出了一个错误
的特征,然后在本地做缓存,如果说同一个特征的错误产生多次的话,服务端只需要知道A用户发生了某某错误,然后错误的详情只需要一次就够了。
这样极大的减少了上报的数据。但是参与hash计算的字段需要特别斟酌,比如url中的参数,id=xxxx 对于不同的id,其实是同一个页面,那么计算就要抛弃这部分特征。
还有像请求的body和response也不应该参与hash计算。
async function getHashId(str) {
const hashBuffer = await crypto.subtle.digest('SHA-256', new TextEncoder().encode(str + (config?.HASH_SALT || '')));
const hashArray = Array.from(new Uint8Array(hashBuffer));
return hashArray.map(b => b.toString(16).padStart(2, '0')).join('');
}为了减少sdk的体积,计算hash部分直接采用浏览器原生支持的 crypto,它的兼容性是ok的
| 浏览器 / 版本 | 支持状态 | 备注 |
|---|---|---|
| Chrome ≥ 37 | ✅ 完全支持 | 自 2014 年起支持,包含所有核心方法 |
| Firefox ≥ 34 | ✅ 完全支持 | 2014 年起支持,早期版本(<34)仅支持部分方法 |
| Safari ≥ 7 | ✅ 部分支持 | Safari 7-10 支持基础功能,Safari 11+ 完善支持所有现代特性 |
| Edge ≥ 12 | ✅ 完全支持 | 基于 Chromium 的 Edge(≥79)与 Chrome 兼容性一致,早期 Edge(12-78)支持核心功能 |
| IE 11 及以下 | ❌ 不支持 | IE 无原生 Crypto API,需依赖第三方库(如 crypto-js) |
| 移动端浏览器 | ✅ 主流支持 | Chrome for Android、Firefox for Android、Safari on iOS ≥ 8 均支持 |
// hash值在缓存中命中则发送数据如下:
const data = {
sdkver,
sdkInstanceId,
reportEnv,
simple: true,
errId,
latestReq,
type,
page: location.href,
uin: userId || '',
ua: navigator.userAgent,
reqBody: errorDetail?.body || '',
response: errorDetail?.response || ''
};
// 如果hash没命中缓存则发送
const data = {
sdkver,
reportEnv,
sdkInstanceId,
errId,
type,
errorDetail: { ...errorDetail, body: '', response: '' }, // 这部分数据是大头
capture:await captureAndCompress(), // 截图数据也很大
page: location.href,
latestReq,
ua: navigator.userAgent,
uin: userId || '',
reqBody: errorDetail?.body || '',
response: errorDetail?.response || '',
};截图处理
另外对于截图数据也做了特殊处理,截图生成时会检查,是否有x秒内已经生成过截图,如果有则本次直接给上次截图数据的id,本次错误上报就不提交截图数据了。
captureAndCompress 函数的相关逻辑如下:
if (time - latestCaptureTime < config.CATCH_SCREEN_INTERVAL * 1000) {
if (await waitUntil(() => !!lastImgHash, { interval: 200 })) {
res({ img: '', hash: lastImgHash });
} else {
res({ img: '', hash: '' });
}
return;
}这样也可以节省大量的上报体积,因为截图只是辅助定位问题,并不是每次错误都需要。
报文压缩
- 对上报数据做转换,对一些结构化的字段做转换,例如type=1表示运行时错误,type=2表示网络错误。
- 对每个上报字段做截断处理,防止上传过大的数据,比如超过1000个字符,截断
- 序列化处理,最终发送的数据做序列化
例如上面的要发送的数据是这样的:
const data = {
sdkver,
reportEnv,
sdkInstanceId,
errId,
type,
errorDetail: { ...errorDetail, body: '', response: '' }, // 这部分数据是大头
capture:await captureAndCompress(), // 截图数据也很大
page: location.href,
latestReq,
ua: navigator.userAgent,
uin: userId || '',
reqBody: errorDetail?.body || '',
response: errorDetail?.response || '',
};实际真实请求发送的时候做序列化,发送的数据:
const data=[1007,1,'xxxxxxx',......,'{code:0,data:{},message:""}'];这样可以保持上报数据的体积是尽量小的。
上报策略
上报时机
上报类型的请求通常都要使用页面卸载也能尽量发送请求的方式,早期仅能使用 navigator.sendBeacon 来发送数据,但是其有一些限制,不能很好的检查到发送是否真正的
成功,后来fetch支持了 keepalive 参数,因此对于上报类型的请求可以优先使用fetch的 keepalive,这样在发生请求错误的时候可以缓存下来要上报的数据,加入重试
机制,尽量保证数据遗漏少,也能和sendBeacon一样在页面卸载之后仍然发送请求。
我写了一个降级处理的上报数据函数
function sendData(data) {
if (document.visibilityState === 'visible') {
return fetch('/report', {
method: 'POST',
body: JSON.stringify(data),
keepalive: true
})
.then(res => {
if (!res.ok){
// 加入失败队列
addCacheQueue(JSON.stringify(data));
}
return res;
})
.catch(error => {
navigator.sendBeacon('/report', JSON.stringify(data));
});
}
return navigator.sendBeacon('/report', JSON.stringify(data));
}
断联重报机制
我给上报模块设计了一个断联重报机制,当上报数据发送失败的时候,会缓存下来,等下次上报数据发送成功的时候,会把缓存的数据一起发送。
setInterval(checkCacheQueue,10*1000);
// checkCacheList源码
function checkCacheQueue(){
// 从cache模块读取缓存列表,如果有缓存,则每隔5秒处理一条缓存数据重发直到队列为空
// 使用队列,如果继续失败,又重新加入到队列尾
}Sdk采集控制
{
REPORT: true, // 是否上报
HASH_SALT: '', // 用于给hash加点偏移,生成一套新的唯一错误id
REQ_URL: '/report/data', // 上报url
REPORT_HOST: ['^.*xxxx.xxx.com'], // 上报域名名单
ASK_WHEN_ERR_CNT: [600, 3], // 同一错误多少秒内连续多少次后询问用户是否主动上报
ASK_INTERVAL: 10, // 两次询问间隔至少多少s
SAME_ERR_ONLY_ID: true, // 已经上报过的错误,只上报errid
SHOW_ASK_HOST: ['^.*xxxx.xxx.com'],// 显示询问的域名
CATCH_SCREEN: true, // 截图
CATCH_SCREEN_INTERVAL: 5, // 两次截图间隔s,中间使用直接用上一张
CATCH_SCREEN_TIMEOUT: 10, // 截图超时
CATCH_SCREEN_SIZE: [0.3, 0.3], // 截图比例压缩
CATCH_SCREEN_QUALITY: 0.3, // 压缩质量
REQ_CACHE_CNT: 20, // 保留多少条请求记录
REQ_CACHE_REQ_RESP: false, // 请求是否上报请求和返回
REP_SUBSTR_LEN: 1000, // response上报时截取最大字符
MIN_VER: 1002 // 上传的sdk最低版本要求
}Sdk因为是通过umd单文件加载,对于sdk需要的一些配置数据,都放在一个json文件挂到cdn,事实上也可以走服务端,但是我选cdn的原因是为了加快sdk的初始化速度(这样可以让sdk尽早完成初始化), 走服务端接口的话,速度上肯定 是不如cdn的静态文件的,但是相应的也有缺点,那就是cdn本身有缓存,有些时候浏览器独特而玄幻的缓存策略,会让你明明更新了cdn文件,也刷新了缓存,但是仍然还会在好几天后仍然收到老配置的sdk上报 了数据,这个问题怎么取舍就完全看自己了,我认为各有各的优势。
服务端设计
服务端设计
服务端的设计其实没有太多复杂的地方,这不是第一个高并发的服务,因此设计上没有什么特别的地方,服务端用什么写都可以,什么框架也都可以,对于这种非密集运算的服务来说, Nodejs是完全胜任的,收到数据后也不会做过多的清洗,服务端相对于前端sdk来说,复杂的是数据逻辑,包括清洗落库、错误数据的状态维护。
数据库选择
为了方便数据落库、结构灵活、以及从数百万上千万数据中快速检索,数据库我选用了MongoDB,其特性跟这个需求非常的契合,比较困难的是其对比关系型数据来说,联合查询的语句比较麻烦, 需要考虑复杂关系的集合之间的联合查询是否好实现的问题。
集合关系设计
我设计的集合主要的和错误数据相关的集合有:
- 错误详情数据
- 上报记录
- 截图
- 忽略错误配置
- 告警配置
- 错误状态
- 统计汇总
这其中我只说一下前2个,核心的设计是错误上报会先检查错误是否在 详情数据 集合中已经存在,如果不存在则写入 详情数据 集合然后写入 上报记录,
如果已经存在 详情数据 集合,则只写入 上报记录 集合。简而言之就是 上报记录 是错误每一次发生的log,任何错误发生一次记录一次,而这些错误最终会关联到一个错误详情数据上。
错误详情schema如下:
import { Prop, Schema, SchemaFactory } from '@nestjs/mongoose';
@Schema({ timestamps: true })
export class ErrorInfo {
@Prop({ required: true, index: true })
errId: string;
@Prop()
firstReportId: string;
@Prop()
type: number;
@Prop()
name?: string;
@Prop()
msg?: string;
@Prop([
{
func: { type: String },
url: { type: String },
line: { type: String },
col: { type: String },
},
])
stack?: { func: string; url: string; line: string; col: string }[];
@Prop()
more?: string;
@Prop()
url?: string;
@Prop()
method?: string;
@Prop()
body?: string;
@Prop()
status?: string;
@Prop()
statusText?: string;
@Prop()
response?: string;
}
export const ErrorInfoSchema = SchemaFactory.createForClass(ErrorInfo);上报记录的shcema如下
import { Prop, Schema, SchemaFactory } from '@nestjs/mongoose';
@Schema({ timestamps: true })
export class ReportExtra {
@Prop({ required: true, index: true })
errId: string;
@Prop({ required: true, index: true })
reportId: string;
@Prop()
screen: boolean;
@Prop()
sdkver: string;
@Prop()
ip: string;
@Prop()
page: string;
@Prop({ index: true })
path: string;
@Prop()
uin: string;
@Prop()
reqBody: string;
@Prop()
response: string;
@Prop()
ua: string;
@Prop({ index: true })
type: number;
@Prop()
sdkInstanceId: string;
@Prop([
{
url: { type: String },
status: { type: String },
ms: { type: String },
headers: { type: Object },
},
])
latestReq?: {
url: string;
status: string;
ms: string;
headers: { [key: string]: string };
}[];
}
export const ReportExtraSchema = SchemaFactory.createForClass(ReportExtra);
这两个schema通过errId(hash值)来进行一个关联。并且支持了环境切分,让这套上报支持不同的环境错误数据。
我们从这张图可以看到,左侧是此错误发生的记录,发生人、发生时间等,他们都共享右侧的错误堆栈、错误信息这些数据,这些数据来自于错误详情,只有错误首次被收录时才写入。
运行错误:
网络错误:
继续看这张图的右侧这些上下文数据全部都来自于上报记录,用户表示左侧列表中某一条数据的对应发生时的一些环境信息。
错误解决及观测
错误数据都收集上来了,现在这些错误数据如何来驱动开发者去关注、修复?
在我们内部这个系统打通了内部需求管理系统、通信工具,因此可以做到:
错误触发告警到群内的相关人员—>人员去对错误数据维护状态--->生成需求单---> 解决错误--->发布--->维护错误状态。
这样就形成了一个错误从诞生到消亡的工作流程闭环。
数据工作台的设计
为此我做了一套后台工作台,包含了错误列表、错误详情、关联错误分析(同一用户同一次访问产生的错误)、错误状态维护
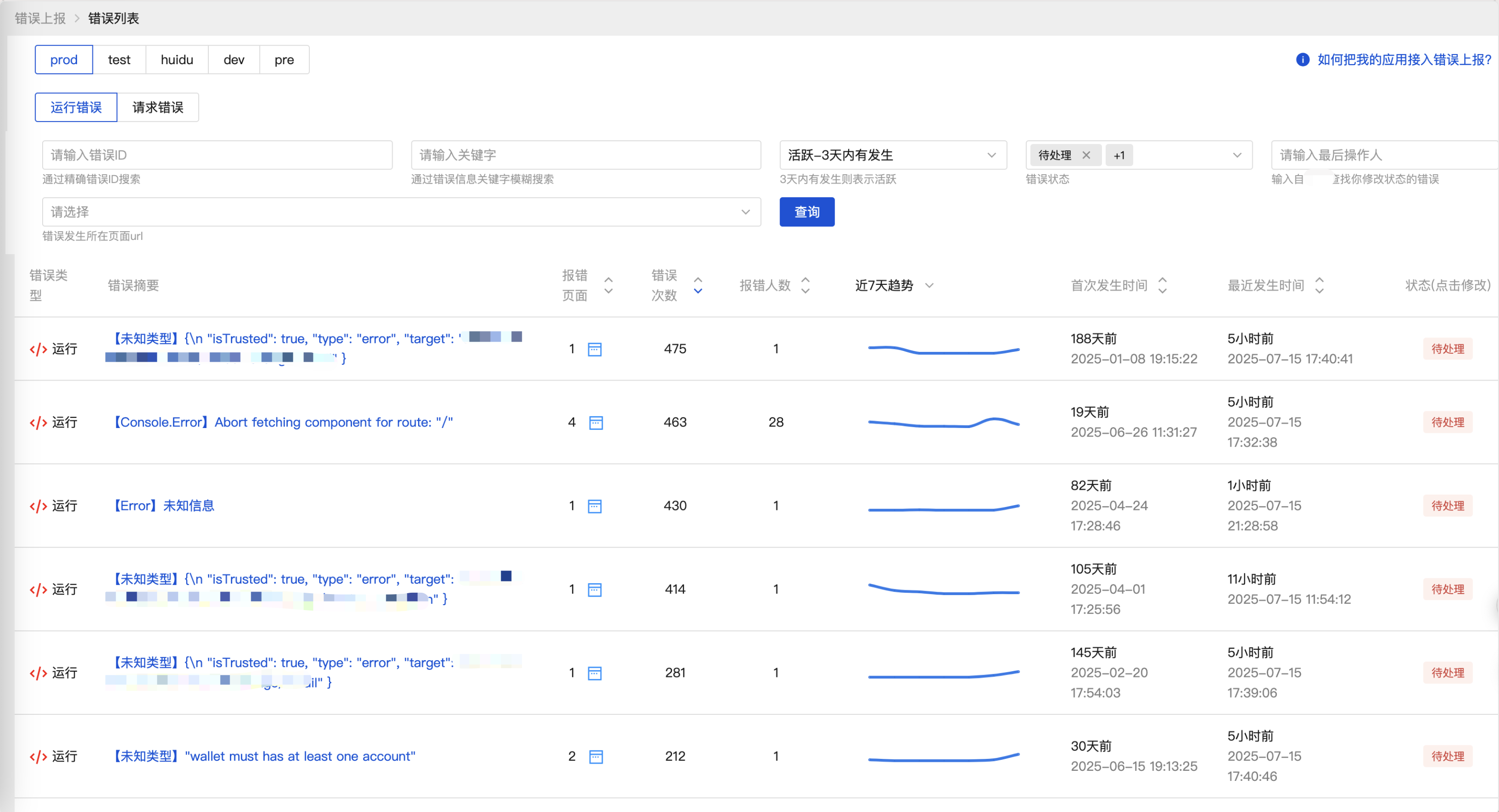
统计分析
通过定时任务、增量扫描新落库的错误数据,生成统计数据,给工作台列表检索以及告警数据生成提供基础数据。
其结合schema如下
@Schema({ timestamps: true })
export class StatInfo {
@Prop({ required: true, index: true, unique: true })
errId: string;
@Prop([
{
name: { type: String },
msg: { type: String },
status: { type: String },
url: { type: String },
more: { type: String },
},
])
errorDetail?: {
name: string;
msg: string;
status: string;
url: string;
more: string;
}[];
@Prop({ required: true })
type: number;
@Prop()
pathCount: number;
@Prop()
totalCount: number;
@Prop()
uinCount: number;
@Prop()
firstTime: string;
@Prop()
lastTime: string;
@Prop([String])
pathList: string[];
@Prop()
isActive: number;
@Prop({ type: Object })
errorStatus: any;
}告警逻辑设计
告警的设计主要分为两部分,一个是错误数据的统计、分析、告警策略配置、策略命中触发告警。
告警策略
告警策略部分配置是保存在系统配置数据中(MongDB)的,策略如下:
- 某个错误(基于errId)发生次数总和大于x次,影响人数总和大于y人
- 某个错误(基于errId)上次告警时间距离当前时间大于t秒
- 某个错误(基于errId)目前仍然处于活跃状态(3天内有发生)
- 告警时间段(例如早8点到晚10点)
满足如上策略的错误将会触发告警,第一点策略的设计出发点是,避开错误偶发,因此配置总次数以及影响范围,如果个别人出现则可以不予关注,因为需要排除个体差异化使用环境带来的问题。 比如浏览器类别、某个测试人员在mock环境测试;第二点是为了防止高频错误突发导致告警轰炸;第三点则是对于一些没有手动维护但是得到修复的错误进行告警屏蔽,错误不再发生告警的意义也 没有了;第四点是支持设置符合使用的团队的告警时间段;
告警配置
针对我们自己的系统,我设计了告警配置和人的关联方案,基于错误path和告警人的关联,通常我们这里不同的业务应用会使用不同的path子应用,因此使用path来关联责任人变得可行, 告警配置的schema如下:
@Schema()
export class AlarmAccount {
@Prop()
type: number;
@Prop()
path: string;
@Prop([String])
account: string[];
@Prop({ default: 1 })
priority: number;
}告警触发
告警的触发也是通过定时任务,扫描增量错误数据,落入告警集合内,然后定时扫描告警集合内符合触发告警的错误数据,推送到群中,at相关责任人。
其结合schema如下
export class Alarm {
@Prop({ type: String, required: true, index: true, unique: true })
errId: string;
//告警记录创建时间
@Prop()
createTime: number;
//上次告警时间
@Prop()
lastAlarmTime: number;
// 最后发生事件
@Prop()
lastHappenTime: number;
//告警总次数
@Prop()
totalCount: number;
//告警总人数
@Prop([String])
totalUser: string[];
//上个区间告警次数
@Prop()
preCount: number;
//上个区间告警人数
@Prop([String])
preUser: string[];
//当前区间次数
@Prop()
currCount: number;
//当前区间人数
@Prop([String])
currUser: string[];
//已告警次数
@Prop()
alarmCount: number;
//关联查询出异常详情信息
@Prop({ type: Object })
statInfo: any;
}多实例定时任务锁
定时任务如果运行在云原生要处理好多pod运行的情况,因此要设计锁模式,避免多个pod同时跑定时任务导致数据出现问题。要么专门起一个定时服务,如果不专门单独起定时服务,加逻辑锁的 时候要做好逻辑锁,可以借助redis,我是通过MongoDB+双重检查逻辑来实现的锁,在pod数量不多的情况下,可以避免同时运行。
扩展方向
错误上报部分的逻辑差不多就是这些了,我的本意也就是希望它仅仅是收集错误,但是用着用着领导们还希望能加入收集性能数据, 这也确实是有的前端上报会做的事情,比如收集首屏渲染时间、资源加载时间、加载成功率等,这些都是未来可以考虑的方向。
最后,如果读到这里,非常感谢您的耐心阅读,这是我从0到1建设这个上报平台的一些关键设计探讨,后面我又时间我也想写写通用前端存储服务的设计与应用 。
欢迎转载,原创不易,转载请注明出处。
